

Stored Procedures, what are they good for?
Before you add, “Absolutely nothing”, let’s just dwell a bit into a practical implementation of a Stored Procedure directly in Canvas Apps, so without any additional logic from Power Automate during the execution. Before we can jump straight into the example, I figured why not make some of the steps that we need to do before, a bit more explicit, including a way it could be done, not the only way!
One of the best use cases of stored procedures in Power Apps from my perspective, is without question, introducing merge statement as an alternative to patch, when we’re dealing with multiple records. Performance is out of this world in comparison to patch, at least that is my personal opinion, and the code maintainability is also quite straight forward. Additionally, I can make other non-canvas app people happy by saying that a lot of my code exists in a SQL form, rather than PowerFX, that is both a pro and a con, I suppose.
Creating the basics
Before demonstrating the example, we’re gonna need some sample tables as well as some sample records. I’ll happily write the code for the tables myself, but I’ll ask ChatGPT to create the sample values, and I’ll also ask ChatGPT to write the Stored Procedure.
So, first I wanna introduce a seperate Schema, we’ll call it CustomerBudgetApp
CREATE SCHEMA CustomerBudgetApp;After this, we’ll introduce two tables, one for customers and one for their budget amounts. An important notion in general for Power Apps and the ability to do writeback into SQL tables, is that the specific tables must have a primary key defined. While this is not true when we insert using either Power Automate or a Stored Procedure, I still tend to do it everytime, even if it’s an Identity column.
CREATE TABLE [CustomerBudgetApp].[BudgetAmounts](
[rowid] [INT] IDENTITY(1,1) NOT NULL PRIMARY KEY,
[Customer_Key] [INT] NOT NULL,
[Q1Amt] [DECIMAL](18, 0) NULL,
[Q2Amt] [DECIMAL](18, 0) NULL,
[Q3Amt] [DECIMAL](18, 0) NULL,
[Q4Amt] [DECIMAL](18, 0) NULL,
[BudgetID] [INT] NOT NULL,
[CreatedBy] [NVARCHAR](30) NULL)The Customer_Key is the Unique Identifier for the customer, in this case dealt with as an integer. The Q1-Q4Amt is the amounts for Q1 to Q4, I prefer this over the total, as it gives me a lower granularity. One could also split this into months, or sum it for a year if that’s more interesting. The BudgetID is generally useless in this scenario, however if we look a bit further down the line, we might wanna introduce multiple budget versions, that could simply be Budget2024 and Budget2025, and a BudgetID will make that easier to deal with. The CreatedBy column is just to enter whoever triggered the creation of the record in question. It serves no real purpose in this scenario, other than traceability.
CREATE TABLE [CustomerBudgetApp].[Customers](
[Customer_Key] [INT] NOT NULL PRIMARY KEY,
[CustomerName] [NVARCHAR](255) NULL,
[AmountInvoicedHours_12mth] [DECIMAL](18, 2) NULL,
[AmountBudgettedLastPeriod] [DECIMAL](18, 2) NULL,
[CustomerFlag] [NVARCHAR](50) NULL)We already covered the Customer_Key, and the CustomerName is somewhat selfexplanatory. The two amount columns contains respectively the amount invoiced for the past 12 months for said customer, as well as the previous budget amount. Finally, the CustomerFlag defines whether the customer is a new customer or an existing customer – one could argue that NVARCHAR(50) for that is waaaay too big.
For the sample values, I get lazy and ask ChatGPT to help me out. My prompt to the free variant of it, is the following:
I have the following T-sql statement, can you generate some arbitrary yet fitting values for it?
The CustomerFlag needs to have the value "New" or "Existing", determining whether it's a new or existing customer. Output should be an insert statement.
[Customer_Key] [INT] NOT NULL PRIMARY KEY,
[CustomerName] [NVARCHAR](255) NULL,
[AmountInvoicedHours_12mth] [DECIMAL](18, 2) NULL,
[AmountBudgettedLastPeriod] [DECIMAL](18, 2) NULL,
[CustomerFlag] [NVARCHAR](50) NULLAnd ChatGPT is happy to oblige and returns me a T-SQL script that does indeed generate values for me.
INSERT INTO YourTableName
([Customer_Key], [CustomerName], [AmountInvoicedHours_12mth], [AmountBudgettedLastPeriod], [CustomerFlag])
VALUES
(1, 'Acme Corporation', 1520.50, 1200.75, 'Existing'),
(2, 'Beta Solutions', 785.00, 800.00, 'New'),
(3, 'Gamma Industries', 1245.75, 1100.00, 'Existing'),
(4, 'Delta Dynamics', 350.00, 300.50, 'New'),
(5, 'Epsilon Enterprises', 980.00, 950.25, 'Existing'),
(6, 'Zeta Ventures', 635.25, 700.00, 'New'),
(7, 'Eta Technologies', 1470.00, 1400.00, 'Existing'),
(8, 'Theta Innovations', 800.50, 850.75, 'New'),
(9, 'Iota Systems', 1125.00, 1100.00, 'Existing'),
(10, 'Kappa Solutions', 420.75, 450.00, 'New');In my prompt to ChatGPT I did forget to include the Table name, so I’ll have to edit that manually, but ChatGPT does inform me of that. The fault is all mine, I cannot blame it for this one.
Creating the Stored Procedure
Next up, I put together a canvas app using a template I have laying around, with the recently introduced Yaml code copy/paste functionality, that made this post a lot quicker than I had anticipated at first.
I have added the two tables to my application, and now we just need to introduce the Stored Procedure to the application as well, but before getting to that point, we need to create the Stored Procedure. While I could “just” write this myself, I’ll once more ask ChatGPT to do it, as it simply is quicker at writing than I am, and when I know exactly what I need, then ChatGPT is quite good at delivering the results.
My prompt is the following, and once more I forgot the table name. Some mistakes I guess I’ll never learn..
I need a T-SQL Stored Procedure that runs a merge statement against the following table:
[Customer_Key] [INT] NOT NULL,
[Q1Amt] [DECIMAL](18, 0) NULL,
[Q2Amt] [DECIMAL](18, 0) NULL,
[Q3Amt] [DECIMAL](18, 0) NULL,
[Q4Amt] [DECIMAL](18, 0) NULL,
[BudgetID] [INT] NOT NULL,
[CreatedBy] [NVARCHAR](30) NULL)
It needs to take two parameters @Json with nvarchar(max), which needs to be opened WIth an OpenJson statement. All the columns in the Json statement match the names of the table definition. The second parameter is @CreatedBy, and should be used to fill that column of the table. If the BudgetID / Customer_Key combination already exists, then it should update, if it doesn't exist then insert. When you write the OpenJSON statement, please refer to the json as ‘$.columnname’ChatGPT replied with the following stored procedure:
CREATE PROCEDURE MergeCustomerBudget
@Json NVARCHAR(MAX),
@CreatedBy NVARCHAR(30)
AS
BEGIN
-- Begin transaction
BEGIN TRANSACTION;
-- Merge statement
MERGE INTO YourTableName AS target
USING (
SELECT
[Customer_Key],
[Q1Amt],
[Q2Amt],
[Q3Amt],
[Q4Amt],
[BudgetID]
FROM OPENJSON(@Json)
WITH (
[Customer_Key] INT '$.Customer_Key',
[Q1Amt] DECIMAL(18, 0) '$.Q1Amt',
[Q2Amt] DECIMAL(18, 0) '$.Q2Amt',
[Q3Amt] DECIMAL(18, 0) '$.Q3Amt',
[Q4Amt] DECIMAL(18, 0) '$.Q4Amt',
[BudgetID] INT '$.BudgetID'
)
) AS source
ON (target.[Customer_Key] = source.[Customer_Key] AND target.[BudgetID] = source.[BudgetID])
-- Update existing records
WHEN MATCHED THEN
UPDATE SET
target.[Q1Amt] = source.[Q1Amt],
target.[Q2Amt] = source.[Q2Amt],
target.[Q3Amt] = source.[Q3Amt],
target.[Q4Amt] = source.[Q4Amt],
target.[CreatedBy] = @CreatedBy
-- Insert new records
WHEN NOT MATCHED THEN
INSERT ([Customer_Key], [Q1Amt], [Q2Amt], [Q3Amt], [Q4Amt], [BudgetID], [CreatedBy])
VALUES (source.[Customer_Key], source.[Q1Amt], source.[Q2Amt], source.[Q3Amt], source.[Q4Amt], source.[BudgetID], @CreatedBy);
-- Commit transaction
COMMIT TRANSACTION;
END
While this may look a bit daunting, especially if SQL is not an expression of comfort for you, it is not that complicated when we’re just doing an insert and an update. First it unpacks the JSON that will come from the Power App, after that it checks the matching condition between the source (data from the Power App) and the target (data already in SQL), and if there is a match for the given row, it will simply update that which is already there, and if there is no match, it will insert it as a new record. We could also introduce a layer that does the deletes, if something exists in source but does not exist in target.
The lovely part of the stored procedure is the performance of it, but that is something we’ll cover in another post. For now we will focus on how to execute it from Power Apps.
Adding the SP to a canvas app
First up is of course adding it to the application, and that is done the same way we add a table. So we’ll navigate to the usual Add data menu, select our connection, if that already exists, and then in the pop-up where we select our table, we can change the navigation to show stored procedures instead.
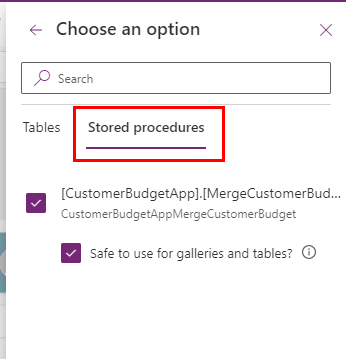
It now looks like just another table in our Data view.
To execute the stored procedure the syntax is quite close to what it was when running a Power Automate flow as well. Just remember to include a manual refresh of your tables after the stored procedure succesfully runs, as that is not something that is done implicitly, like it is when we’re patching.
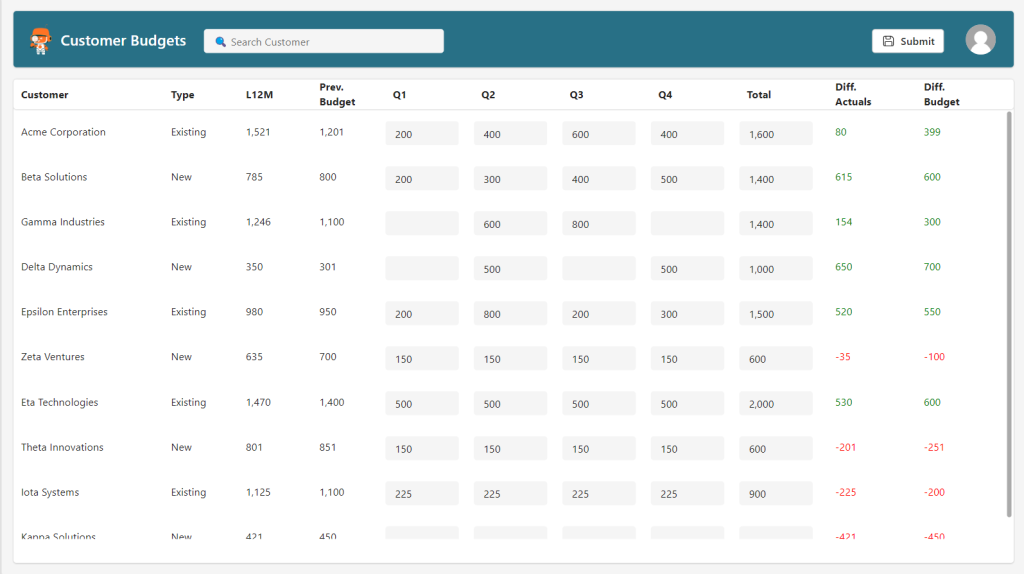
skillsthrills.CustomerBudgetAppMergeCustomerBudget({Json: JSON(col_Budgets, JSONFormat.IndentFour), CreatedBy: User().Email});
Refresh('CustomerBudgetApp.BudgetAmounts');ClearCollect(col_Budgets, Filter('CustomerBudgetApp.BudgetAmounts', BudgetID = v_budgetkey));So, I pass a collection with all my budget changes and the email of the logged in user, to the stored procedure, and then from there it does all the heavy lifting. Afterwards I do a refresh of my table that has the amounts, and I run a ClearCollect, so my collection also has the newest values.
The content of the collection looks like the following:
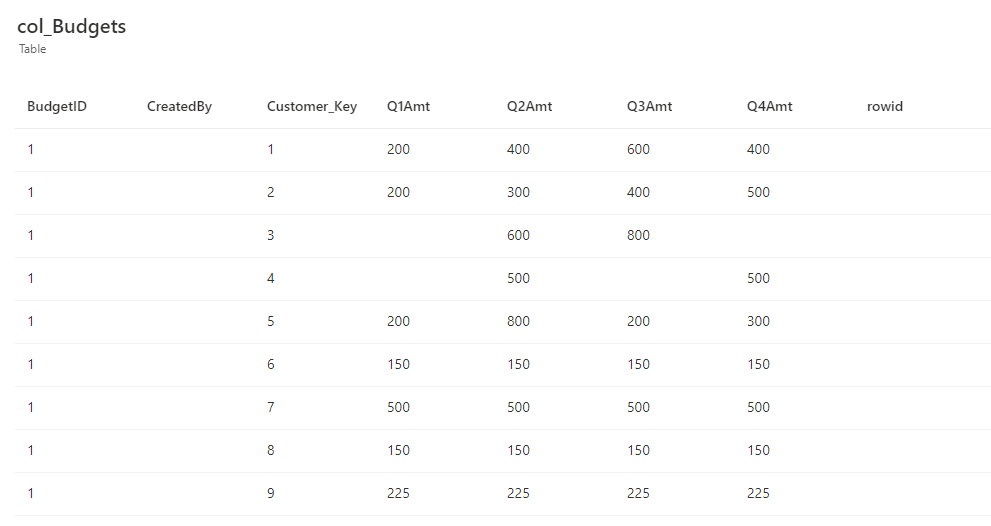
The contents of the collection is managed by a variable that determines the BudgetID, in this case that’s a very simple OnStart property:
Set(v_budgetkey, 1);
ClearCollect(col_Budgets, Filter('CustomerBudgetApp.BudgetAmounts', BudgetID = v_budgetkey));The editing of the collection, happens on the input fields, and looks like the following for the quarterlies:
OnChange property:
Patch(col_Budgets, Coalesce(LookUp(col_Budgets, Customer_Key = ThisItem.Customer_Key), Defaults(col_Budgets)), {Customer_Key: ThisItem.Customer_Key, Q1Amt:Value(TextInputCanvas2.Value), Q2Amt:Value(TextInputCanvas2_1.Value) , Q3Amt:Value(TextInputCanvas2_2.Value), Q4Amt:Value(TextInputCanvas2_3.Value), BudgetID: v_budgetkey})
Value property:
Text(LookUp(col_Budgets, Customer_Key = ThisItem.Customer_Key, Q1Amt),"#,##")And the following is for the total:
OnChange property:
Patch(col_Budgets, Coalesce(LookUp(col_Budgets, Customer_Key = ThisItem.Customer_Key), Defaults(col_Budgets)), {Customer_Key: ThisItem.Customer_Key, Q1Amt:Value(Self.Value/4), Q2Amt:Value(Self.Value/4) , Q3Amt:Value(Self.Value/4), Q4Amt:Value(Self.Value/4), BudgetID: v_budgetkey})
Value property:
Text(Sum(TextInputCanvas2.Value,TextInputCanvas2_1.Value,TextInputCanvas2_2.Value,TextInputCanvas2_3.Value),"#,##")Doing it this way, allows for a very nice flow between using quarterly amounts, and total amounts. If we change a quarterly amount, the total will change too, but none of the other quarters will change. If we enter a total amount, all the quarterlies will become 1/4th of the total. The purpose of the Text function is simply to introduce thousand seperators, for a nicer presentation of the numbers in question.
Closing Thoughts
Up next, is a performance comparison between a variety of patching methods including patching a collection, patching with ForAll and then of course a Stored Procedure which we just looked at. Generally the Stored Procedure starts making sense, in my perspective, when we’re dealing with more than 10 records at a time. Until then, you’re more than fine with Patch, and Patch can also do say 100 records. But by then you’ll probably have a better time with a Stored Procedure.
A final and very important note, is that stored procedures are a SQL exclusive, they do not exist in Dataverse unfortunately. If you need to patch a lot of records in Dataverse and the performance of Patch is not good enough for you, then you can take a look at Dataverse plugins instead.


Pingback: Writeback – how low can you go? – A Power Platform blog by Chris Hansen